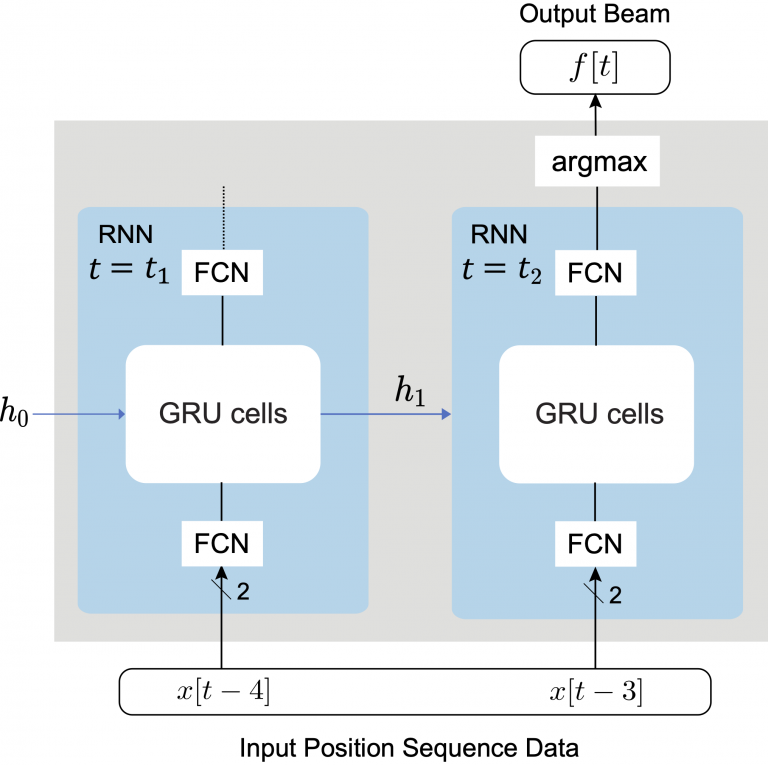
|
1
|
./unit1/radar_data/data_18605_01-59-49_537.npy
|
./unit1/radar_data/data_18607_01-59-49_737.npy
|
./unit1/radar_data/data_18609_01-59-49_937.npy
|
./unit1/radar_data/data_18611_01-59-50_137.npy
|
./unit1/radar_data/data_18613_01-59-50_337.npy
|
./unit1/camera_data/image_BS2_20220_01-59-49.jpg
|
./unit1/camera_data/image_BS2_20222_01-59-49.jpg
|
./unit1/camera_data/image_BS2_20224_01-59-49.jpg
|
./unit1/camera_data/image_BS2_20226_01-59-49.jpg
|
./unit1/camera_data/image_BS2_20228_01-59-50.jpg
|
./unit1/lidar_data/Frame_37195_01_59_50_705.ply
|
./unit1/lidar_data/Frame_37199_01_59_50_905.ply
|
./unit1/lidar_data/Frame_37203_01_59_51_105.ply
|
./unit1/lidar_data/Frame_37207_01_59_51_305.ply
|
./unit1/lidar_data/Frame_37211_01_59_51_505.ply
|
./unit2/GPS_data/gps_location_30935.txt
|
./unit2/GPS_data/gps_location_30937.txt
|
./unit1/mmWave_data/mmWave_power_20228.txt
|
9
|
|
2
|
./unit1/radar_data/data_24937_02-10-22_744.npy
|
./unit1/radar_data/data_24939_02-10-22_947.npy
|
./unit1/radar_data/data_24941_02-10-23_147.npy
|
./unit1/radar_data/data_24943_02-10-23_347.npy
|
./unit1/radar_data/data_24945_02-10-23_547.npy
|
./unit1/camera_data/image_BS2_27095_02-10-22.jpg
|
./unit1/camera_data/image_BS2_27097_02-10-22.jpg
|
./unit1/camera_data/image_BS2_27099_02-10-22.jpg
|
./unit1/camera_data/image_BS2_27101_02-10-23.jpg
|
./unit1/camera_data/image_BS2_27104_02-10-23.jpg
|
./unit1/lidar_data/Frame_49860_02_10_23_891.ply
|
./unit1/lidar_data/Frame_49864_02_10_24_091.ply
|
./unit1/lidar_data/Frame_49868_02_10_24_291.ply
|
./unit1/lidar_data/Frame_49872_02_10_24_491.ply
|
./unit1/lidar_data/Frame_49876_02_10_24_691.ply
|
./unit2/GPS_data/gps_location_37291.txt
|
./unit2/GPS_data/gps_location_37293.txt
|
./unit1/mmWave_data/mmWave_power_27104.txt
|
31
|
|
3
|
./unit1/radar_data/data_759_01-30-04_898.npy
|
./unit1/radar_data/data_761_01-30-05_098.npy
|
./unit1/radar_data/data_763_01-30-05_298.npy
|
./unit1/radar_data/data_765_01-30-05_498.npy
|
./unit1/radar_data/data_767_01-30-05_698.npy
|
./unit1/camera_data/image_BS2_819_01-30-04.jpg
|
./unit1/camera_data/image_BS2_821_01-30-04.jpg
|
./unit1/camera_data/image_BS2_824_01-30-05.jpg
|
./unit1/camera_data/image_BS2_826_01-30-05.jpg
|
./unit1/camera_data/image_BS2_828_01-30-05.jpg
|
./unit1/lidar_data/Frame_1503_01_30_05_985.ply
|
./unit1/lidar_data/Frame_1507_01_30_06_185.ply
|
./unit1/lidar_data/Frame_1511_01_30_06_385.ply
|
./unit1/lidar_data/Frame_1515_01_30_06_585.ply
|
./unit1/lidar_data/Frame_1519_01_30_06_785.ply
|
./unit2/GPS_data/gps_location_13022.txt
|
./unit2/GPS_data/gps_location_13024.txt
|
./unit1/mmWave_data/mmWave_power_828.txt
|
2
|
|
4
|
./unit1/radar_data/data_20936_02-03-42_642.npy
|
./unit1/radar_data/data_20938_02-03-42_836.npy
|
./unit1/radar_data/data_20940_02-03-43_036.npy
|
./unit1/radar_data/data_20942_02-03-43_236.npy
|
./unit1/radar_data/data_20944_02-03-43_436.npy
|
./unit1/camera_data/image_BS2_22749_02-03-42.jpg
|
./unit1/camera_data/image_BS2_22751_02-03-42.jpg
|
./unit1/camera_data/image_BS2_22753_02-03-42.jpg
|
./unit1/camera_data/image_BS2_22755_02-03-42.jpg
|
./unit1/camera_data/image_BS2_22757_02-03-43.jpg
|
./unit1/lidar_data/Frame_41857_02_03_43_782.ply
|
./unit1/lidar_data/Frame_41861_02_03_43_982.ply
|
./unit1/lidar_data/Frame_41865_02_03_44_182.ply
|
./unit1/lidar_data/Frame_41869_02_03_44_382.ply
|
./unit1/lidar_data/Frame_41873_02_03_44_582.ply
|
./unit2/GPS_data/gps_location_33280.txt
|
./unit2/GPS_data/gps_location_33282.txt
|
./unit1/mmWave_data/mmWave_power_22757.txt
|
39
|
|
5
|
./unit1/radar_data/data_21256_02-04-14_638.npy
|
./unit1/radar_data/data_21258_02-04-14_838.npy
|
./unit1/radar_data/data_21260_02-04-15_038.npy
|
./unit1/radar_data/data_21262_02-04-15_238.npy
|
./unit1/radar_data/data_21264_02-04-15_438.npy
|
./unit1/camera_data/image_BS2_23097_02-04-14.jpg
|
./unit1/camera_data/image_BS2_23099_02-04-14.jpg
|
./unit1/camera_data/image_BS2_23101_02-04-14.jpg
|
./unit1/camera_data/image_BS2_23103_02-04-14.jpg
|
./unit1/camera_data/image_BS2_23105_02-04-15.jpg
|
./unit1/lidar_data/Frame_42497_02_04_15_778.ply
|
./unit1/lidar_data/Frame_42501_02_04_15_978.ply
|
./unit1/lidar_data/Frame_42505_02_04_16_178.ply
|
./unit1/lidar_data/Frame_42509_02_04_16_378.ply
|
./unit1/lidar_data/Frame_42513_02_04_16_578.ply
|
./unit2/GPS_data/gps_location_33600.txt
|
./unit2/GPS_data/gps_location_33602.txt
|
./unit1/mmWave_data/mmWave_power_23105.txt
|
47
|